
robots 是站點與 spider 溝通的重要渠道,站點通過 robots 文件聲明該網站中不想被搜索引擎收錄的部分或者指定搜索引擎只收錄特定的部分。請注意,僅當您的網站包含不希望被搜索引擎收錄的內容時,才需要使用 robots.txt 文件。
什么是robots.txt
robots 是站點與 spider 溝通的重要渠道,站點通過 robots 文件聲明該網站中不想被搜索引擎收錄的部分或者指定搜索引擎只收錄特定的部分。請注意,僅當您的網站包含不希望被搜索引擎收錄的內容時,才需要使用 robots.txt 文件。
Robots協議(也稱為爬蟲協議、機器人協議等)的全稱是“網絡爬蟲排除標準”(Robots Exclusion Protocol),網站通過Robots協議告訴搜索引擎哪些頁面可以抓取,哪些頁面不能抓取。
搜索引擎機器人訪問網站時,首先會尋找站點根目錄有沒有 robots.txt文件,如果有這個文件就根據文件的內容確定收錄范圍,如果沒有就按默認訪問以及收錄所有頁面。另外,當搜索蜘蛛發現不存在robots.txt文件時,會產生一個404錯誤日志在服務器上,從而增加服務器的負擔,因此為站點添加一個robots.txt文件還是很重要的。
SEO中的作用
從SEO角度來說,剛上線的網站,由于頁面較少,robots.txt做不做都可以,但隨著頁面的增加,robots.txt的SEO作用就體現出來了,主要表現在以下幾個方面。
- 優化搜索引擎機器人的爬行抓取
- 阻止惡意抓取,優化服務器資源
- 減少重復內容出現在搜索結果中
- 隱藏頁面鏈接出現在搜索結果中
如何查看
如:http://m.kartiktrivedi.com/robots.txt
訪問此鏈接,即可看到本站的robots.txt文件。
如何設置
方法一:安裝插件:XML Sitemap & Google News feeds,詳見:

方法二: 新建一個名稱為robots.txt文本文件,將相關內容放進去,然后上傳到網站根目錄即可。
放置什么
推薦放入以下內容:
User-agent: *
Disallow: /wp-admin/
Disallow: /wp-content/
Disallow: /wp-includes/
Disallow: /*/comment-page-*
Disallow: /*?replytocom=*
Disallow: /category/*/page/
Disallow: /tag/*/page/
Disallow: /*/trackback
Disallow: /feed
Disallow: /*/feed
Disallow: /comments/feed
Disallow: /?s=*
Disallow: /*/?s=*
Disallow: /*?*
Disallow: /attachment/
具體放啥需要你閱讀以下文件后決定,以上僅為推薦。
各項作用
robots.txt的寫法包括User-agent,Disallow,Allow和Crawl-delay。
- User-agent: 后面填你要針對的搜索引擎,*代表全部搜索引擎
- Disallow: 后面填你要禁止抓取的網站內容和文件夾,/做前綴
- Allow: 后面填你允許抓取的網站內容,文件夾和鏈接,/做前綴
- Crawl-delay: 后面填數字,意思是抓取延遲,小網站不建議使用
1、Disallow: /wp-admin/、Disallow: /wp-content/和Disallow: /wp-includes/
用于告訴搜索引擎不要抓取后臺程序文件頁面。
2、Disallow: /*/comment-page-*和Disallow: /*?replytocom=*
禁止搜索引擎抓取評論分頁等相關鏈接。
3、Disallow: /category/*/page/和Disallow: /tag/*/page/
禁止搜索引擎抓取收錄分類和標簽的分頁。
4、Disallow: /*/trackback
禁止搜索引擎抓取收錄trackback等垃圾信息
5、Disallow: /feed、Disallow: /*/feed和Disallow: /comments/feed
禁止搜索引擎抓取收錄feed鏈接,feed只用于訂閱本站,與搜索引擎無關。
6、Disallow: /?s=*和Disallow: /*/?s=*
禁止搜索引擎抓取站內搜索結果
7、Disallow:?/*?*
禁止搜索抓取動態頁面
8、Disallow: /attachment/
禁止搜索引擎抓取附件頁面,比如毫無意義的圖片附件頁面。
文件詳解
robots文件往往放置于根目錄下,包含一條或更多的記錄,這些記錄通過空行分開(以CR,CR/NL,?or?NL作為結束符),每一條記錄的格式如下所示:
???? ?"<field>:<optional?space><value><optionalspace>"
?在該文件中可以使用#進行注解,具體使用方法和UNIX中的慣例一樣。該文件中的記錄通常以一行或多行User-agent開始,后面加上若干Disallow和Allow行,詳細情況如下:
????User-agent:該項的值用于描述搜索引擎robot的名字。在"robots.txt"文件中,如果有多條User-agent記錄說明有多個robot會受到"robots.txt"的限制,對該文件來說,至少要有一條User-agent記錄。如果該項的值設為*,則對任何robot均有效,在"robots.txt"文件中,"User-agent:*"這樣的記錄只能有一條。如果在"robots.txt"文件中,加入"User-agent:SomeBot"和若干Disallow、Allow行,那么名為"SomeBot"只受到"User-agent:SomeBot"后面的?Disallow和Allow行的限制。
????Disallow:該項的值用于描述不希望被訪問的一組URL,這個值可以是一條完整的路徑,也可以是路徑的非空前綴,以Disallow項的值開頭的URL不會被?robot訪問。例如"Disallow:/help"禁止robot訪問/help.html、/helpabc.html、/help/index.html,而"Disallow:/help/"則允許robot訪問/help.html、/helpabc.html,不能訪問/help/index.html。"Disallow:"說明允許robot訪問該網站的所有url,在"/robots.txt"文件中,至少要有一條Disallow記錄。如果"/robots.txt"不存在或者為空文件,則對于所有的搜索引擎robot,該網站都是開放的。
????Allow:該項的值用于描述希望被訪問的一組URL,與Disallow項相似,這個值可以是一條完整的路徑,也可以是路徑的前綴,以Allow項的值開頭的URL?是允許robot訪問的。例如"Allow:/hibaidu"允許robot訪問/hibaidu.htm、/hibaiducom.html、/hibaidu/com.html。一個網站的所有URL默認是Allow的,所以Allow通常與Disallow搭配使用,實現允許訪問一部分網頁同時禁止訪問其它所有URL的功能。
????使用"*"and"$":Baiduspider支持使用通配符"*"和"$"來模糊匹配url。
????"*"?匹配0或多個任意字符
?????"$"?匹配行結束符。
最后需要說明的是:百度會嚴格遵守robots的相關協議,請注意區分您不想被抓取或收錄的目錄的大小寫,百度會對robots中所寫的文件和您不想被抓取和收錄的目錄做精確匹配,否則robots協議無法生效。
用發舉例:
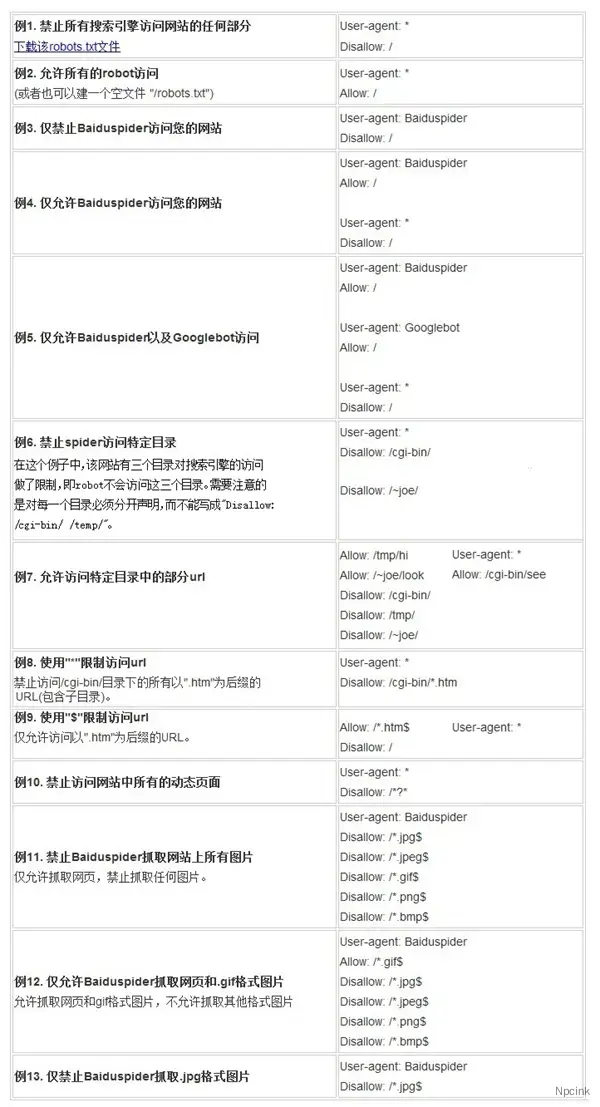
來源于:https://blog.csdn.net/aa3236925/article/details/78993924
但是在實際的操作中,絕大多數的網站,在其撰寫上都存在或多或少的欠缺,甚至由于技術性的錯誤撰寫,還會導致網站降權、不收錄、被K等一系列問題的出現。對于這一點,A5營銷,包括我,在對客戶的SEO診斷過程中,會經常遇到,可以算是很多站點的通病。今天寫出這篇文章,就是來做一個分享:關于robots.txt協議,你寫對了嗎?
一:設置成Allow全站點抓取
百度收錄的越多,網站的排名越高?這是絕大多數站長的認為,事實上也是如此。但是也并非絕對成立:低質量的頁面收錄,會降低網站的排名效果,這一點你考慮到了嗎?
如果你的網站結構不是非常的清晰,以及不存在多余的“功能”頁面,不建議對網站開全站點的抓取,事實上,在A5的SEO診斷中,只遇到極少數的一部分網站,可以真正的做到全站點都允許抓取,而不做屏蔽。隨著功能的豐富,要做到允許全站點抓取,也不太可能。
二:什么樣的頁面不建議抓取
對于網站功能上有用的目錄,有用的頁面,在用戶體驗上可以得到更好的提升。但是搜索引擎方面來講,就會造成:服務器負擔,比如:大量的翻頁評論,對優化上則沒有任何的價值。
除此外還包含如:網站做了偽靜態處理后,那么就要將動態鏈接屏蔽掉,避免搜索引擎抓取。用戶登錄目錄、注冊目錄、無用的軟件下載目錄,如果是靜態類型的站點,還要屏蔽掉動態類型的鏈接Disallow: /*?* 為什么呢?我們舉個例子來看:
上面是某客戶網站發現的問題,被百度收錄的原因是:有人惡意提交此類型的鏈接,但是網站本身又沒有做好防護。
三:撰寫上的細節注意事項
方法上來講,絕大多數的站長都明白,這里就不做多說了,不明白的站長,可以上百度百科看一下。今天這里說一些不常見的,可能是不少站長的疑問。
1、舉例:Disallow; /a 與Disallow: /a/的區別,很多站長都見過這樣的問題,為什么有的協議后加斜杠,有的不加斜杠呢?筆者今天要說的是:如果不加斜杠,屏蔽的是以a字母開頭的所有目錄和頁面,而后者代表的是屏蔽當前目錄的所有頁面和子目錄的抓取。
通常來講,我們往往選擇后者更多一些,因為定義范圍越大,容易造成“誤殺”。
2、JS文件、CSS需要屏蔽嗎?不少網站都做了這個屏蔽,但是筆者要說的是:google站長工具明確的說明:封禁css與js調用,可能會影響頁面質量的判斷,從而影響排名。而對此,我們做了一些了解,百度方面同樣會有一定影響。
3、已經刪除的目錄屏蔽,很多站長往往刪除一些目錄后,怕出現404問題,而進行了屏蔽,禁止搜索引擎再抓取這樣的鏈接。事實上,這樣做真的好嗎?即使你屏蔽掉了,如果之前的目錄存在問題,那么沒有被蜘蛛從庫中剔除,同樣會影響到網站。
建議最佳的方式是:將對應的主要錯誤頁面整理出來,做死鏈接提交,以及自定義404頁面的處理,徹底的解決問題,而不是逃避問題。